

Kubernetes Networking Across On-Prem Datacenters with BGP, ECMP, and BFD
Introduction
Kubernetes powers a vast array of mission-critical applications, many of which operate in on-premises datacenters spanning multiple sites. Unlike public cloud environments, which abstract networking complexity behind managed services, on-premises deployments expose the underlying challenges of routing Pods and Services efficiently across a distributed infrastructure. Designing a resilient, scalable, and observable network fabric is crucial to ensure predictable connectivity, high availability, and seamless failover behavior for workloads.
In this blog, we dive deep into how modern datacenter networking concepts—such as Clos fabrics, dynamic routing with BGP, ECMP load balancing, and BFD rapid failover—can be leveraged to integrate Kubernetes clusters directly into enterprise network fabrics.
Core Networking Challenges in On-Prem Kubernetes
On-premises Kubernetes networking presents unique challenges that require careful architectural consideration:
-
Scalable Routing: As the number of nodes, Pods, and Services grows, traditional Layer 2 overlays and static routing become bottlenecks. Without native Layer 3 routing visibility, scaling beyond a few hundred nodes is difficult.
-
Rapid Failover: Links or nodes can fail at any time. Slow detection and rerouting can render workloads unreachable, causing downtime for critical applications.
-
Multi-Datacenter Connectivity: Applications often span multiple datacenters. Maintaining consistent routing policies and ensuring Service reachability across sites are essential for high availability and global access.
-
Operational Simplicity: Managing IPs, routing tables, and point-to-point links in a large fabric can quickly become overwhelming. Automation and dynamic routing protocols are required to reduce human error and maintain consistency.
Clos Fabrics and Dynamic Routing
A Clos network, commonly referred to as a spine-leaf architecture, forms the backbone of modern datacenter fabrics. It provides high bandwidth, predictable latency, and multiple equal-cost paths to enable resilient connectivity.
- Leaf Switches connect directly to servers, including Kubernetes nodes, handling BGP peering with upstream layers or external networks. They forward traffic to spine switches for inter-leaf communication.
- Spine Switches interconnect leaf switches, creating a high-speed backbone that ensures low latency, redundancy, and ECMP-enabled multiple-path traffic forwarding.
- Border Leaf Switches act as gateways to external networks, connecting the datacenter to WANs, other datacenters, or the Internet.
- In very large-scale deployments, a Super Spine layer can be introduced above the spine layer to interconnect multiple spine blocks, further reducing oversubscription and improving multi-datacenter scalability.
Dynamic routing protocols, particularly BGP, allow nodes and services to advertise their presence directly into the fabric, providing a scalable, loop-free routing topology. ECMP (Equal-Cost Multi-Path) spreads traffic across multiple spine-leaf paths, optimizing bandwidth utilization and providing redundancy.
Scaling Control Planes with IPv6 BGP Unnumbered
Traditional IPv4 BGP deployments require dedicated subnets for each point-to-point link, which quickly consumes IP space in large fabrics.
IPv6 BGP Unnumbered solves this problem:
- Uses link-local IPv6 addresses for BGP session establishment.
- No need to allocate /31 or /30 subnets per link.
- IPv4 routes for Pods and Services are still exchanged.
This approach simplifies automation, reduces operational overhead, and ensures consistent routing without wasting precious IPv4 addresses.
Key takeaway: IPv6 handles the control plane; IPv4 remains for workloads.
Running FRR on Kubernetes Nodes
FRR (Free Range Routing) is an open-source routing software suite that provides implementations of standard routing protocols such as BGP, OSPF, RIP, and IS-IS. It allows network devices—including Linux servers, virtual machines, and Kubernetes nodes—to participate in IP routing just like traditional routers.
In simpler terms, FRR turns a regular machine into a fully capable router, enabling it to advertise, receive, and manage network routes dynamically. It’s widely used in data centers, cloud networking, and Kubernetes environments to integrate workloads directly into the network fabric, support ECMP load balancing, and enable fast failover with BFD.
Running FRR on nodes converts each Kubernetes worker into a mini-router:
- Advertises Pod CIDRs and Service VIPs directly to the fabric.
- Supports BFD for rapid failure detection (<1 second).
- Uses loopbacks as stable next-hops for ECMP.
- Avoids overlay encapsulation overhead, enabling native L3 routing visibility.
This architecture ensures that all workloads are first-class citizens on the network, visible to switches and routers for direct routing, allowing the datacenter fabric to see Pods and Services as native IP prefixes, not just encapsulated traffic.
Addressing Model
A clean addressing scheme simplifies routing and policy management:
-
Node Segment (10.10.19.x): Each Kubernetes node is assigned a unique loopback IP that serves as its BGP router ID. For example, Node1 could have
10.10.19.10. This address remains stable even if the physical interface changes. -
Pod Segment (10.10.20.x): Pods receive dynamic IPs from per-node CIDRs. For instance, a Pod on Node1 might get
10.10.20.5. These IPs are advertised automatically by FRR, reducing manual configuration. -
Service Segment (10.10.21.x): ClusterIP or LoadBalancer VIPs are assigned
/32routes and advertised to the fabric via node loopbacks. This ensures services are reachable across the network, enabling high availability and ECMP forwarding.
Sample FRR Configuration
frr version 8.1
frr defaults traditional
hostname cp1
log syslog informational
no ipv6 forwarding
service integrated-vtysh-config
interface eno5
ipv6 nd ra-interval 6
no ipv6 nd suppress-ra
exit
interface eno7
ipv6 nd ra-interval 6
no ipv6 nd suppress-ra
exit
interface lo
ip address 10.10.19.10/32 # Node loopback
ip address 10.10.21.66/32 # Service VIP
ip address 10.10.21.227/32 # Additional VIP
exit
router bgp 65496
bgp router-id 10.10.19.10
bgp bestpath as-path multipath-relax
neighbor TOR peer-group
neighbor TOR remote-as internal
neighbor TOR bfd
neighbor TOR timers 1 3
neighbor eno5 interface peer-group TOR
neighbor eno7 interface peer-group TOR
bgp fast-convergence
address-family ipv4 unicast
network 10.10.19.10/32
network 10.10.21.66/32
network 10.10.21.227/32
redistribute kernel
redistribute connected
exit-address-family
exit
Fabrics Overview
Modern Kubernetes deployments often involve multiple interconnected fabrics:
-
App Fabrics: Individual datacenter clusters advertise node, Pod, and Service routes into the Clos fabric. ECMP load-balances traffic, and BFD enables sub-second failover.
-
DCI Fabric: Interconnects App Fabrics across geographies, sharing routing information and enabling cross-datacenter service reachability.
-
Edge Fabric: Handles north-south traffic, enforces security policies, and routes external traffic to the correct internal services.
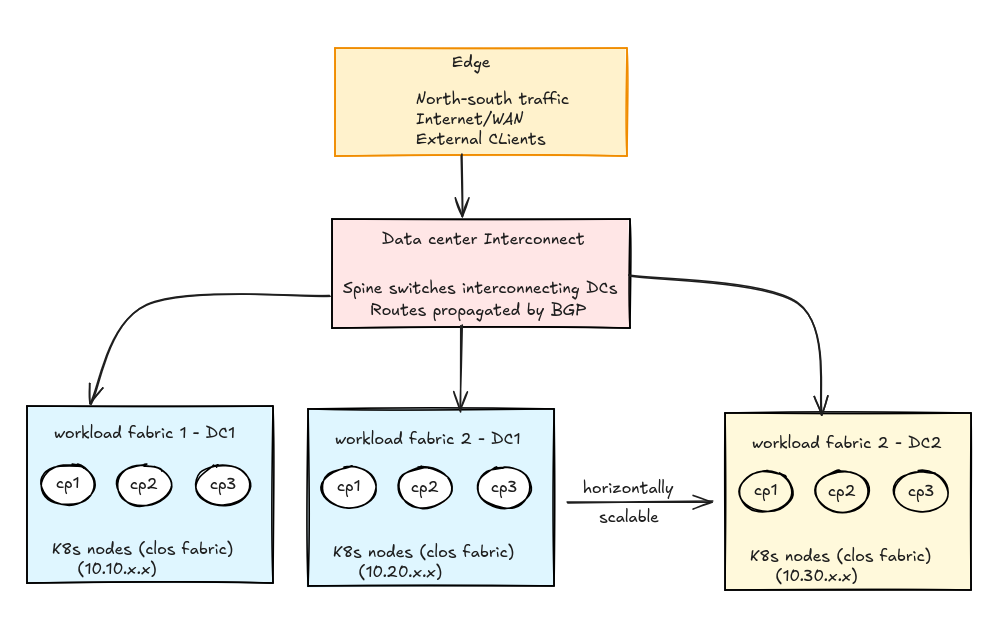
BGP, ECMP, and BFD in Action
Multi-BGP Neighbor Setup
Each Kubernetes node typically peers with two upstream leaf switches. ECMP allows traffic to traverse both uplinks efficiently, while BFD ensures rapid failure detection.
- Service VIPs are advertised from node loopbacks and propagated across the spine-leaf fabric, DCI, and edge networks, providing seamless connectivity even during failures.
- Pod IPs are redistributed automatically from kernel routes, allowing real-time updates without manual intervention.
Service Advertisement Flow
- Node advertises Service VIP to fabric via BGP.
- Leaf switches propagate the route across spines (ECMP paths).
- DCI fabric shares the route across datacenters.
- Edge fabric routes external traffic to the correct node.
- Failures are handled seamlessly, with remaining nodes continuing to advertise VIPs.
Why Service IPs Are Added to Loopback
- Service IPs are virtual and unbound from physical interfaces.
- Assigning them to the node’s loopback makes them stable BGP hosts.
- Advertising these as /32 routes ensures accurate reachability.
- Supports HA and ECMP forwarding of service traffic across the fabric.
Why Pod IPs Are Advertised Automatically
- Pods obtain dynamic IPs within node-specific CIDRs.
- These IPs map to kernel-managed routes automatically.
- FRR redistributes kernel routes, advertising pod presence dynamically.
- Automation reduces manual config and promotes real-time fabric updates.
Extended Theory
BGP Benefits in K8s
- Loop-free routing: BGP prevents routing loops even with multiple paths.
- Scalability: Thousands of nodes and services can be advertised without massive L2 overlays.
- Policy Control: Route-maps and filters can enforce service placement policies.
ECMP Considerations
- Provides load distribution across multiple paths.
- Works best with stable loopback next-hops.
- May require tuning for hash algorithms to avoid uneven traffic flows.
BFD Insights
- Detects link or node failure in milliseconds.
- Reduces downtime by quickly withdrawing unreachable routes.
- Works alongside BGP to trigger failover without waiting for BGP timers.
Best Practices
- Automate FRR deployment using tools like Ansible, Helm charts, or Kubernetes operators.
- Maintain a consistent IP addressing scheme across datacenters to avoid conflicts.
- Actively monitor BGP and BFD sessions for anomalies.
- Automate adding Service IPs into FRR using Cosmolet (an open-source project by PlatformCosmo).
- Secure routing with prefix filters and network policies.
- Regularly test failover scenarios to ensure resilience.
Conclusion
Integrating Kubernetes clusters into Clos fabrics using FRR, BGP, ECMP, and BFD transforms on-premises networking. Pods and Services become natively routable, highly available, and globally reachable across datacenters.
Leveraging IPv6 BGP unnumbered reduces operational complexity, while BFD ensures sub-second failover. This architecture delivers cloud-like networking behavior for enterprises that demand predictable, scalable, and resilient on-premises deployments.
This design delivers cloud-like networking behavior for on-prem deployments — allowing Kubernetes services to remain globally reachable, highly available, and scalable across fabrics.
